A couple of days back, at least 4 people sent me the same link to a tweet from Microsoft Office. They had released a really cool new feature to take a picture of a table and have it imported into the Excel mobile app. This was very cool. I was sent this tweet, because those who know me, knew I was leading the technology development at my startup 9fin, where we also show a similar “party trick” with how we’re able to pull table data from documents and put it flawlessly into Excel. For us, we’ve had this ability for over 2 years now, and we use it internally to power our data processing pipeline of the most comprehensive data on the European High Yield Bond Markets.
If that last line sent you to sleep, or made no sense to you, then we don’t take offence! We know we are quite niche. But that’s the exact reason why we show our “magic excel” demo, as it’s a great way to visually convey for anyone not familiar with the industry, what we can do with data. But for our customers, we never need to bring this up, because our market is not data extraction or OCR technology.
At 9fin we consume, organise and understand the world’s fixed income financial data. Making it easier for investment professionals to search, filter and analyse. At a much higher point in the value chain, we deliver that directly to our clients. Enriching and linking to news, price and contextual data. So they can skip the data entry, and many other steps all together. [1][2][3]
With over $79 trillion AUM [4] globally across all markets, you can see how a small edge in any part of the investment process yields returns.
Digital leaders [in asset management] also realize benefits in the investment process. Some have automated their investment-management agreements with natural language processing, ensuring rapid compliance with client guidelines and allowing portfolio managers to establish positions more quickly. — McKinsey & Company, Achieving digital alpha in asset management, November 2018
So I think it’s not quite right to directly compare 9fin with Excel here, it’s not going to be apples to apples…or even fruits to fruits. But I’m a tech nerd, and I like cool stuff just as much as the next person, so I wanted to see what it could do.
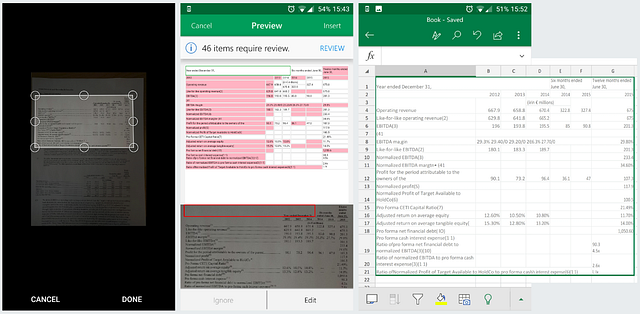

The UX on the Android app is really fluid, but ultimately the tool struggles on the more complex tables…which are way more normal in financial documents. We needed these extractions to be flawless. This is not to knock the MSFT team and the hard work, but it was the same issue that we faced when first starting the company.
Sometimes I refer to 9fin as “the accidental AI company”, because developing Computer Vision and ML systems were not the original plan. The goal was always to serve the most useful and complete data to the bond markets directly to investment professionals, but when trying to populate our systems we hit the problem of data extraction. We tried everything both open source and commercial before we built anything, but none of them were up to the task of bringing structured order to the chaos of the documents we were dealing with. So with a clear problem case to target for, we were guided in our development to eventually solve this for our needs. With only 2 people at most on this project. (Don’t let that hide the difficulty of the challenge!)
Excel is just a convenient output format, but for us the data is represented differently internally, which is what you need to be able to use it in databases, front end screens, APIs and further data processing pipelines.

I think our approach is different;
- we don’t use deep learning all the way down, but rather at the edges in more specialised roles within the system along with other ML techniques.
- It is not fully OCR only, meaning it can adapt to what is in front of it, and pick the best execution path. (We can do OCR).
- we also don’t need to pull your (potentially private) documents into a different cloud you don’t control. Since we also handle millions of pages ourselves, we can deploy a fully trained up static binary to run wherever you want.
- Running on our tuned grid/parallel compute setup, we can process a page in 0.05s wall time.
- A by-product of our system is that we capture every detail, allowing you to be taken back to the exact position within the source document. Plus you can then go “in reverse” and search said documents. [5]
But as I said, we don’t sell data extraction software.
I’m really happy to see this area of tech gain more interest. In this case, of low level extraction, I think this is shaping up to be a battle between document management solutions. The old guard Microsoft, Adobe and the new Dropbox, Google. Which is a fight I’m very happy to not be a part of!
(obligatory xkcd)
— end note —